Dijkstra's algorithm
The algorithm uses a min-priority queue data structure for selecting the shortest paths known so far.Before more advanced priority queue structures were discovered, Dijkstra's original algorithm ran in[8][9] Fredman & Tarjan 1984 proposed a Fibonacci heap priority queue to optimize the running time complexity toThis is asymptotically the fastest known single-source shortest-path algorithm for arbitrary directed graphs with unbounded non-negative weights.If preprocessing is allowed, algorithms such as contraction hierarchies can be up to seven orders of magnitude faster.Dijkstra's algorithm is commonly used on graphs where the edge weights are positive integers or real numbers.One morning I was shopping in Amsterdam with my young fiancée, and tired, we sat down on the café terrace to drink a cup of coffee and I was just thinking about whether I could do this, and I then designed the algorithm for the shortest path.Eventually, that algorithm became to my great amazement, one of the cornerstones of my fame.Dijkstra thought about the shortest path problem while working as a programmer at the Mathematical Center in Amsterdam in 1956.[13] His objective was to choose a problem and a computer solution that non-computing people could understand.[5] A year later, he came across another problem advanced by hardware engineers working on the institute's next computer: minimize the amount of wire needed to connect the pins on the machine's back panel.Every intersection is listed on a separate line: one is the starting point and is labeled (given a distance of) 0.A more general problem is to find all the shortest paths between source and target (there might be several of the same length).As mentioned earlier, using such a data structure can lead to faster computing times than using a basic queue.Notably, Fibonacci heap[19] or Brodal queue offer optimal implementations for those 3 operations.[7]: 198 Yet another alternative is to add nodes unconditionally to the priority queue and to instead check after extraction (u ← Q.extract_min()) that it isn't revisiting, or that no shorter connection was found yet in the if alt < dist[v] block.This can be done by additionally extracting the associated priority p from the queue and only processing further if p == dist[u] inside the while Q is not empty loop.[20] These alternatives can use entirely array-based priority queues without decrease-key functionality, which have been found to achieve even faster computing times in practice.[21] To prove the correctness of Dijkstra's algorithm, mathematical induction can be used on the number of visited nodes.For all other visited nodes v, the dist[v] is already known to be the shortest distance from source already, because of the inductive hypothesis, and these values are unchanged.for any simple graph, but that simplification disregards the fact that in some problems, other upper bounds onIn this case, extract-minimum is simply a linear search through all vertices in Q, so the running time isThe Fibonacci heap improves this to When using binary heaps, the average case time complexity is lower than the worst-case: assuming edge costs are drawn independently from a common probability distribution, the expected number of decrease-key operations is bounded by, giving a total running time of[7]: 199–200 In common presentations of Dijkstra's algorithm, initially all nodes are entered into the priority queue.[12] Moreover, not inserting all nodes in a graph makes it possible to extend the algorithm to find the shortest path from a single source to the closest of a set of target nodes on infinite graphs or those too large to represent in memory.The resulting algorithm is called uniform-cost search (UCS) in the artificial intelligence literature[12][23][24] and can be expressed in pseudocode as Its complexity can be expressed in an alternative way for very large graphs: when C* is the length of the shortest path from the start node to any node satisfying the "goal" predicate, each edge has cost at least ε, and the number of neighbors per node is bounded by b, then the algorithm's worst-case time and space complexity are both in O(b1+⌊C* ⁄ ε⌋).[23] Further optimizations for the single-target case include bidirectional variants, goal-directed variants such as the A* algorithm (see § Related problems and algorithms), graph pruning to determine which nodes are likely to form the middle segment of shortest paths (reach-based routing), and hierarchical decompositions of the input graph that reduce s–t routing to connecting s and t to their respective "transit nodes" followed by shortest-path computation between these transit nodes using a "highway".[25] Combinations of such techniques may be needed for optimal practical performance on specific problems.In 2023, Haeupler, Rozhoň, Tětek, Hladík, and Tarjan (one of the inventors of the 1984 heap), proved that, for this sorting problem on a positively-weighted directed graph, a version of Dijkstra's algorithm with a special heap data structure has a runtime and number of comparisons that is within a constant factor of optimal among comparison-based algorithms for the same sorting problem on the same graph and starting vertex but with variable edge weights.Prim's does not evaluate the total weight of the path from the starting node, only the individual edges.The fast marching method can be viewed as a continuous version of Dijkstra's algorithm which computes the geodesic distance on a triangle mesh.
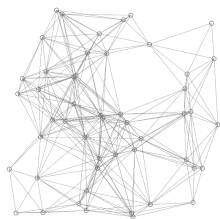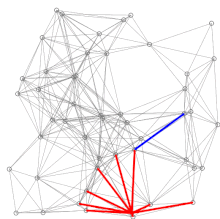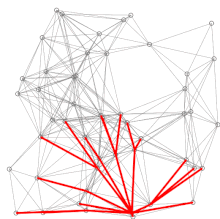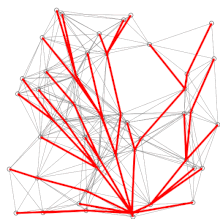

Dykstra's projection algorithmSearch algorithmGreedy algorithmDynamic programmingpriority queueWorst-caseperformancealgorithmshortest pathsroad networkcomputer scientistEdsger W. Dijkstrarouting protocolssubroutineJohnson's algorithmmin-priority queueFibonacci heapasymptoticallyshortest-path algorithmdirected graphscontraction hierarchiespartially orderedmonotonicallyartificial intelligencebest-first searchRotterdamGroningenIt is the algorithm for the shortest pathAmsterdamMathematical Center in AmsterdamPrim's minimal spanning tree algorithmJarníkmotion planningwavefrontheuristicintersectionsneighborrelabelingpseudocodedepth-first searchBrodal queuecorrectnessmathematical inductionbig-O notationadjacency listmatrixsparse graphsself-balancing binary search treebinary heappairing heapaverage caseprobability distributionbidirectionalA* algorithmtransit nodesTarjancomparison-basedbucket queueVan Emde Boas treeradix heaplink-state routing protocolsBellman–Ford algorithmnegative cyclegraph theorytheoretical computer sciencegreedyPrim's algorithmminimum spanning treeBreadth-first searchfast marching methodBellman'sA* search algorithmEuclidean shortest pathFloyd–Warshall algorithmLongest path problemParallel all-pairs shortest path algorithmDijkstra, E. W.CiteSeerXMehlhorn, KurtSanders, PeterTarjan, Robert EndreBibcodeCormen, Thomas H.Leiserson, Charles E.Rivest, Ronald L.Stein, CliffordIntroduction to AlgorithmsRussell, StuartNorvig, PeterDover PublicationsMIT PressMcGraw–HillCommunications of the ACMFredman, Michael LawrenceTarjan, Robert E.Transportation ScienceKnuth, D.E.Information Processing LettersCharles Babbage InstituteRobert Cecil MartinEdsger DijkstraGo To Statement Considered HarmfulOn the Cruelty of Really Teaching Computer ScienceEWD manuscriptsTheoretical computing scienceSoftware engineeringSystems scienceAlgorithm designConcurrent computingDistributed computingFormal methodsProgramming methodologyProgramming language researchProgram designdevelopmentSoftware architecturePhilosophy of computer programming and computing scienceShlomi DolevPer Brinch HansenTony HoareOle-Johan DahlLeslie LamportDavid ParnasCarel S. Scholten Adriaan van WijngaardenNiklaus Wirth